Skip to content
PartPacker
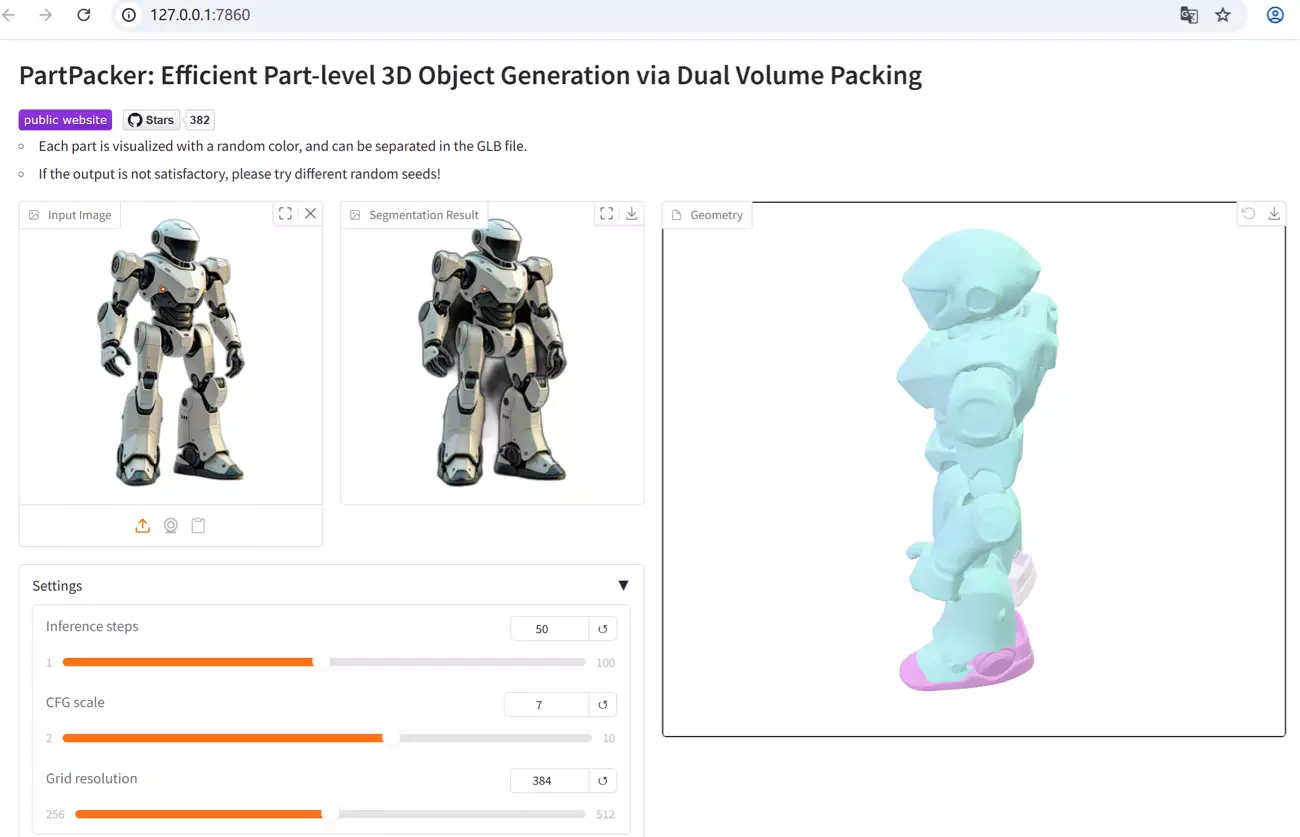
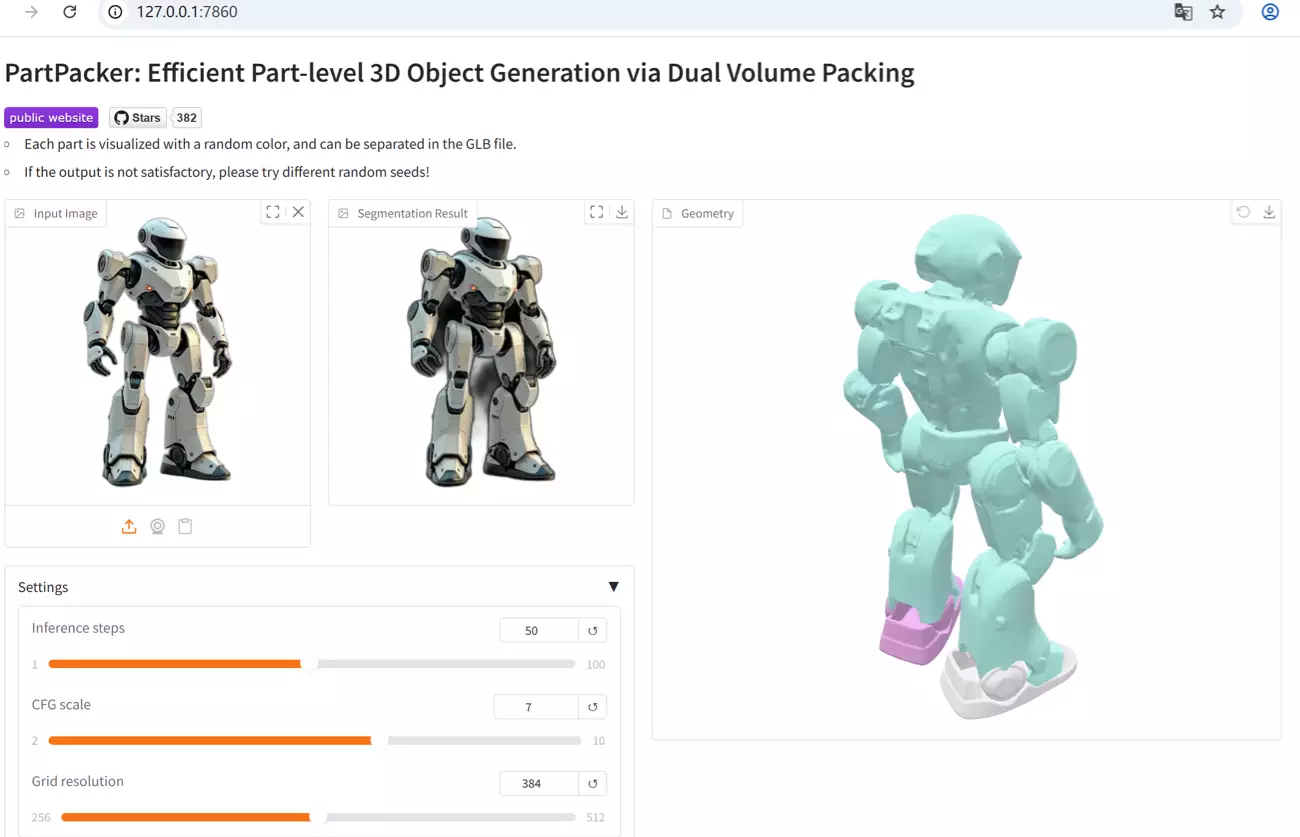
PartPacker enables part-level 3D object generation from single-view images
Features
Screenshots
System Requirements
Minimum 16GB RAM. 12GB+ storage recommended.
Windows 10/11: NVIDIA GPU with 10GB+ VRAM required
Note: For NVIDIA GPUs, install a newer driver.Introduction
Note: For non-commercial use only. Commercial use, services, or product development are prohibited. See LICENSE for details.
PartPacker is a project developed by the NVlabs team under NVIDIA. It is the official implementation of the research "Efficient Part-level 3D Object Generation via Dual Volume Packing". The model enables part-level 3D object generation from single-view images.
Technical Features and Advantages
- Part-level 3D Generation Capability: It can achieve part-level generation of 3D objects from single-view images, making the generated 3D objects more detailed and accurate in structure.
- Efficient Dual Volume Packing Technology: The project provides a dual volume packing implementation, which can process raw glb meshes into two separate meshes. This technology helps to generate and process 3D objects more efficiently.
- Multi-GPU Support: It supports multi-GPU inference, and can automatically manage memory and transfer data between GPUs. In this mode, the memory pressure per GPU can be reduced, and better performance can be obtained with 2 or more GPUs, which well meets the needs of different users for hardware resources.
- Flexible Dependency Installation: The dependency installation method is flexible. Users can choose to use requirements.txt or requirements.lock.txt to install dependencies according to their needs. By default, it uses PyTorch's built-in attention mechanism, and also supports users to explicitly use flash-attn.
- Convenient Inference and Application: It provides a variety of inference methods, including VAE reconstruction of meshes, Flow 3D generation based on images, and starting a local application through Gradio, which is convenient for users to operate and use.
Function Introduction
- Model Inference: It can perform operations such as VAE reconstruction of meshes and Flow 3D generation from images. During the inference process, about 10GB of GPU memory is required (when using float16).
- Data Processing: It can process raw glb meshes and convert them into two independent meshes, providing a basis for subsequent 3D object generation.
- Pretrained Model Support: Pretrained models are provided. Users can download them from Hugging Face and place them in the specified pretrained folder for quick use.
LicenseNVIDIA Source Code License